概要
前回までの続き。
- (2021-06-16)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み1章 ニューラルネットワークの基礎
- (2021-06-17)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み2章 Keras のインストールと API
- (2021-06-18)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み3章 畳み込みニューラルネットワーク
- (2021-06-19)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み4章 GAN と WaveNet
- (2021-06-20)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み5章 単語分散表現
- (2021-06-21)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み6章 リカレントニューラルネットワーク
- (2021-06-23)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み7章 さまざまなディープラーニングのモデル
1章でニューラルネットワークの概要を回収し、2章でそれらを Keras でどう表すのか回収した。3、4、5章では畳み込みニューラルネットワークで画像分類と画像贋作と音声生成と単語分散表現をした。6章ではリカレントニューラルネットワークで系列データを処理した。7章では CNN でも RNN でもないモデルをいくつかさらったが、実際のところ「どちらでもない」というよりそれらを組み合わせた複雑なモデル、というものだった。
8章で、ようやくこの本は終わりだ。ふいに思い立って、「1日1章読んで1記事にまとめる」挑戦をしてみたが、かなりキツかった。って、総括に入るのは早いな。いかんいかん。8章ではとうとう大ボスである「強化学習」を回収する。
8章をざっくり読んだ
8章のサンプルコード: https://github.com/oreilly-japan/deep-learning-with-keras-ja/tree/master/ch08
- 強化学習 reinforcement learning って何?
- もともとは deep learning の用語ではなくて、行動心理学の用語だ。
- 正しい行動に対して正の報酬が与えられ、間違った行動に対して負の報酬が与えられるもの。うん、フツーだね。
- でもこれまで「学習」はやれてたじゃん、なんでわざわざ新しいことを始めるの? という疑問に対してのアンサー。
- この章では落ちゲーのオートプレイを目指す。
- この学習を、これまでこの本でやってきたことを応用して行うとすれば、ゲーム画面を入力として、出力が3アクションからの洗濯となる分類問題としてモデル化することになるだろう。これはこれでよい。
- が、データセットはどうする? 学習のためには上手な人間のプレイ動画を録画し、プレイ中の各画像を学習データとして用意する必要がある。やってられん。
- だから代わりに、ネットワークにゲームを繰り返しプレイさせ、ボールのキャッチに成功したかどうかフィードバックを与えよう。
- なるほどね、データセットを自分で集めてもらうってことね!
- このアプローチを行うための一般的な手法は、マルコフ決定過程(Markov decision process)という。
- 「エージェントが各エピソードで獲得する報酬の総和を最大にすること」だ。
- エージェント: 学習の主体であるネットワークのこと。
- エピソード: 落ちゲーのボールがキャッチされるか底に落ちるかまでのこと。
- いや、報酬の総和って何?
- 報酬の総和って何?
- ネットワークの目的は、直近の1エピソードで最大の報酬を得ることではない。
- 報酬の総和をあらわす数式は次の通りだ。(えぇー数式ぃー?)
R(t) = r(t) + γ * r(t+1) + γ^2 * r(t+2) + ... + γ^(n-t) * r(n)
= r(t) + γ * ( r(t+1) + γ(r(t+2 + ...)) )
= r(t) + γ * R(t + 1)
- これ↑の各要素の解説。
t: ある時刻。s(t): 時刻 t における環境の状態(ようはゲーム画面のこと)。a(t): 時刻 t における行動。r(t):a(t)に応じて得られる報酬。s(t+1)へ遷移する確率はs(t)とa(t)に依存する。γ: ガンマ。割引率。先の報酬ほど、手に入る確率って低いじゃん? だから先の報酬ほど割引率をかけて報酬を割り引くのだ。γ=0であれば将来の報酬はないことになり、γ=1であれば報酬は必ずある。- いや、数式の理解の仕方、わかんねぇー! とにかく将来含めた報酬の操作を最大にするんだよ!
- 報酬の操作を得る式は手に入れたとして、どうニューラルネットワークで実現すればいい? そこで Q-learning です。
- これはマルコフ決定過程において、ある状態における最適な行動を見つける手法。
- ちょっと混乱してきたので流れを整理すると、「強化学習」の手法は「報酬の総和を最大にすること = マルコフ決定過程」で、それを踏まえてある時点における最適な行動を見つける手法が「Q-learning」だ。
- Q ってのは、割引現在価値を算出する関数。定義はこれ↓
Q( s(t), a(t) ) = max( R(t+1) )- いやわかんねえ! けどとにかくこの Q は最適な行動を見つける関数なのだから、 Q をニューラルネットワークで作ればよいのだよ。(思考停止)
- わかんねえものはとりあえず置いておき、 Q をニューラルネットワークで実装するには?
- これを発表した DeepMind 社の論文においては、3つの畳み込み層と2つの全結合層で出来ている。プーリング層はなし。
- 「畳み込み層はプーリング層と共に」という基準がドンドン崩れていく……。
- 敵対的生成ネットワーク GAN の Generator model もプーリング層がない畳み込み層だったな。
- そうやって作ったニューラルネットワークの中でも、 DeepMind 社が作ったものを Deep Q-network という。
- 別に DeepMind 社が作ったから名前がついているわけではなくて、 NN が Deep Q-network と呼ばれるには条件がある。次↓の3つの工夫がなされていることが条件だ。
- DeepMind の研究の大きな意義は、これらの工夫を行ったことなのだ。
- Experience Replay
- Replay memory から行動結果
( s, a, r, s' ) = (状態、行動、報酬、次の状態)を抽出して学習に利用すること。
- Replay memory から行動結果
- Q-network の固定
- 同じ条件では同じ値を返すようネットワークを固定して学習を安定させること。
- 報酬のクリッピング
- 報酬を、失敗なら -1 成功なら 1 で固定すること。
- ゲームによって -3 とか 5 とか使い分けると設定がむつかしくなるのだ。
- 「3つの工夫」は以上だ。
- exploration vs exploitation って何?
- 強化学習における探索と活用の関係性のことだ。どちらかを多くするともう片方が少なくなる。
- それを記号を使って表現するとこう↓なる。
ε(イプシロン)の確率でランダムに行動して学習(exploration)し、1-εの確率で学習結果を活用して行動(exploitation)。
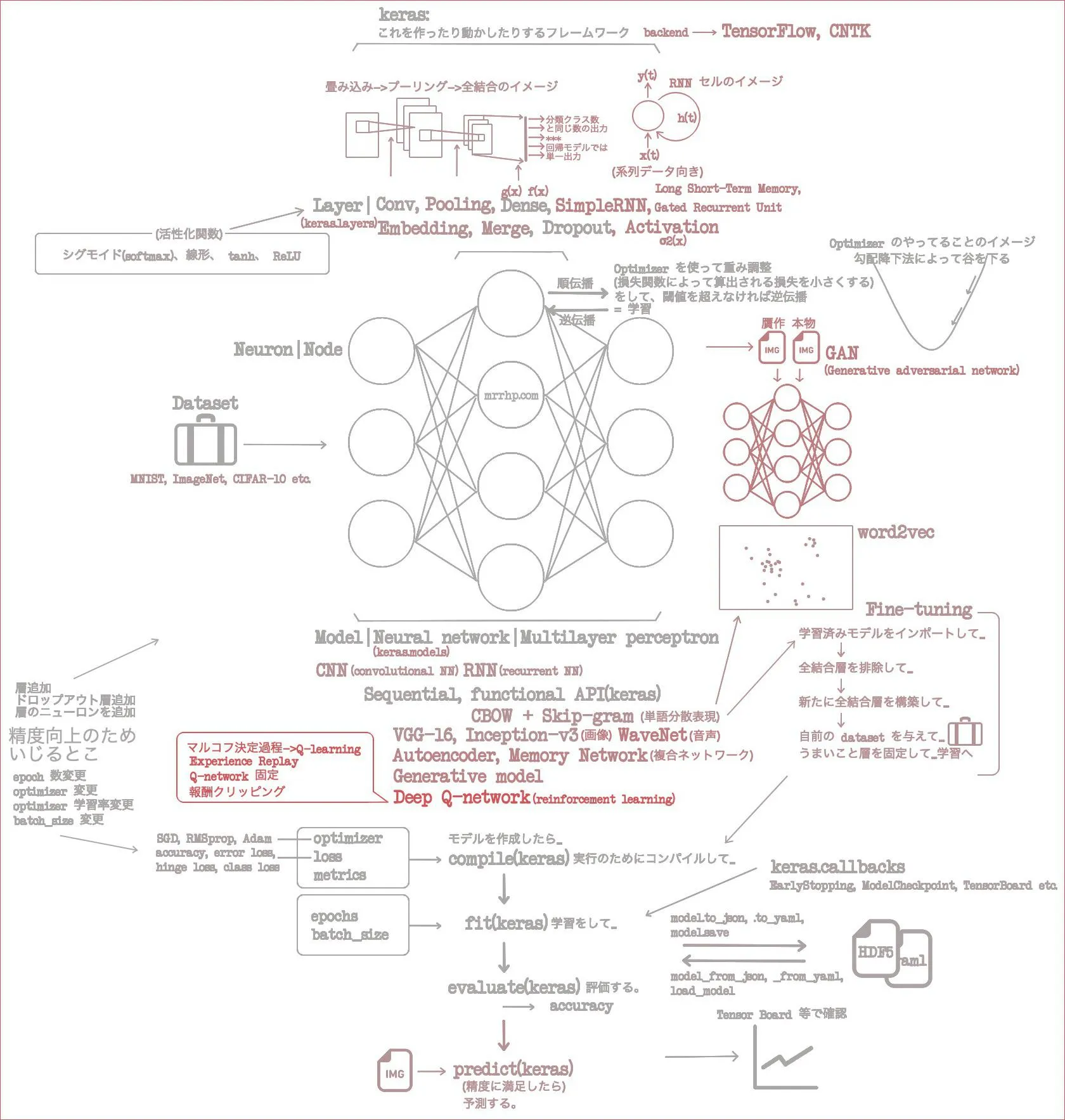
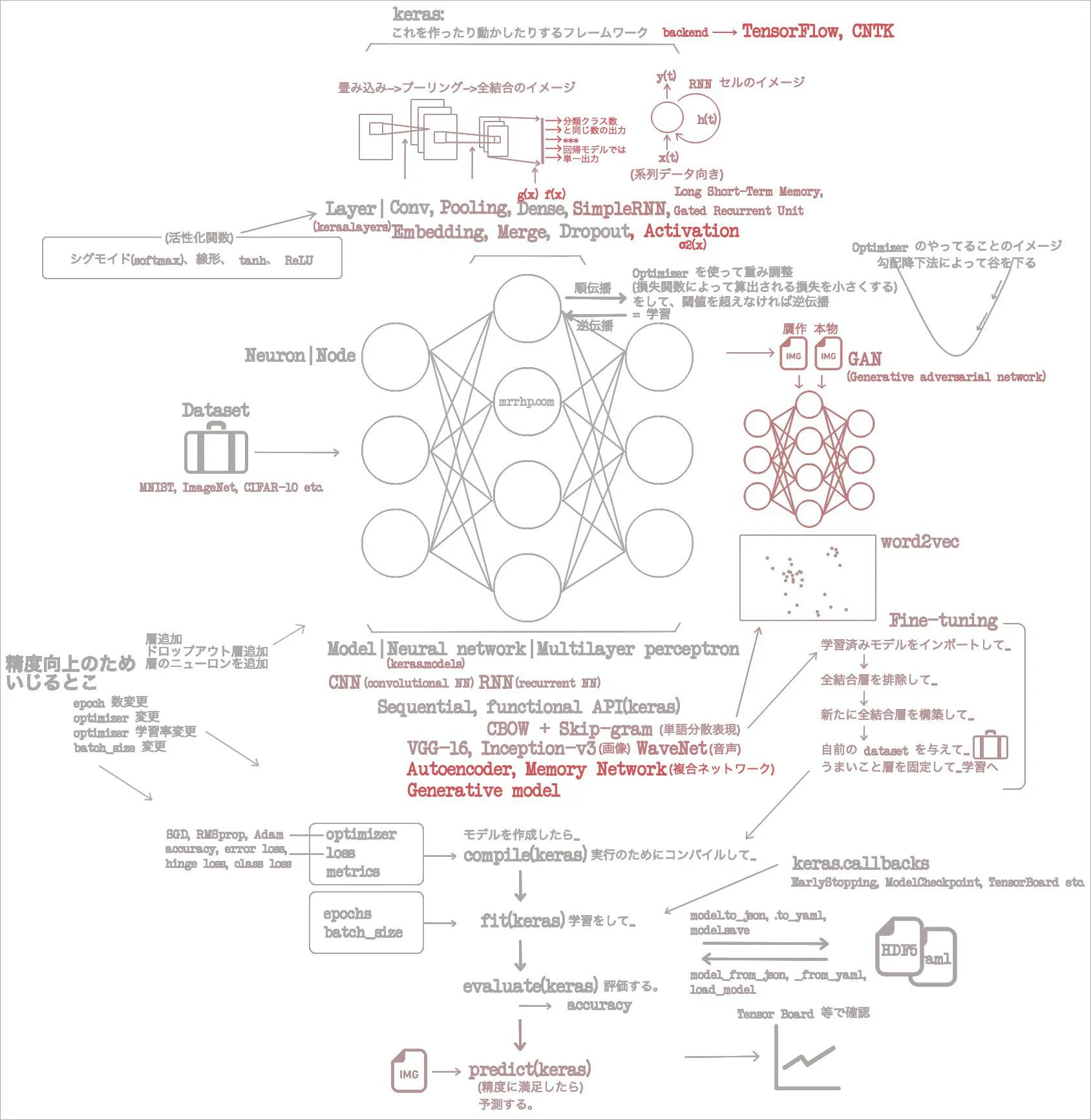
おしまい。総括は次の記事にまかせて、ここではマイ「イメージの流れ」図を更新して終了しよう。