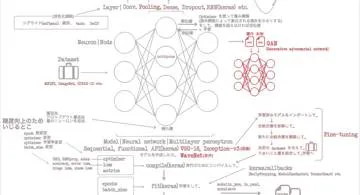
概要
前回までの続き。
- (2021-06-16)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み1章 ニューラルネットワークの基礎
- (2021-06-17)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み2章 Keras のインストールと API
- (2021-06-18)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み3章 畳み込みニューラルネットワーク
- (2021-06-19)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み4章 GAN と WaveNet
- (2021-06-20)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み5章 単語分散表現
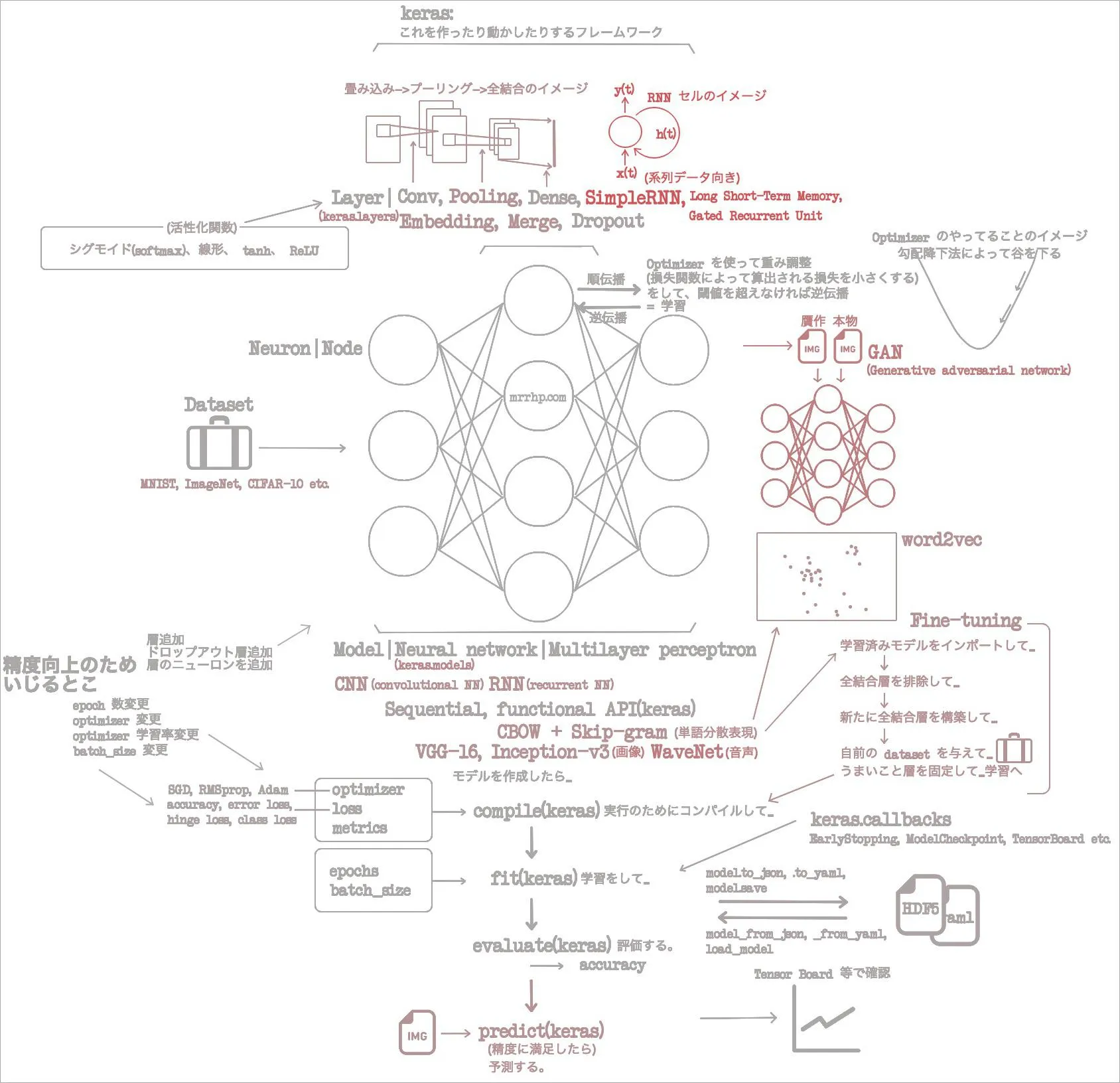
1章で概念をざっと回収し、2章で Keras のクラスをざっと回収した。3、4章で CNN を使い画像分類と画像贋作をこなした。音声生成もこなした。5章では画像も音声も超えて、自然言語処理のひとつ、単語分散表現を CNN でやった。
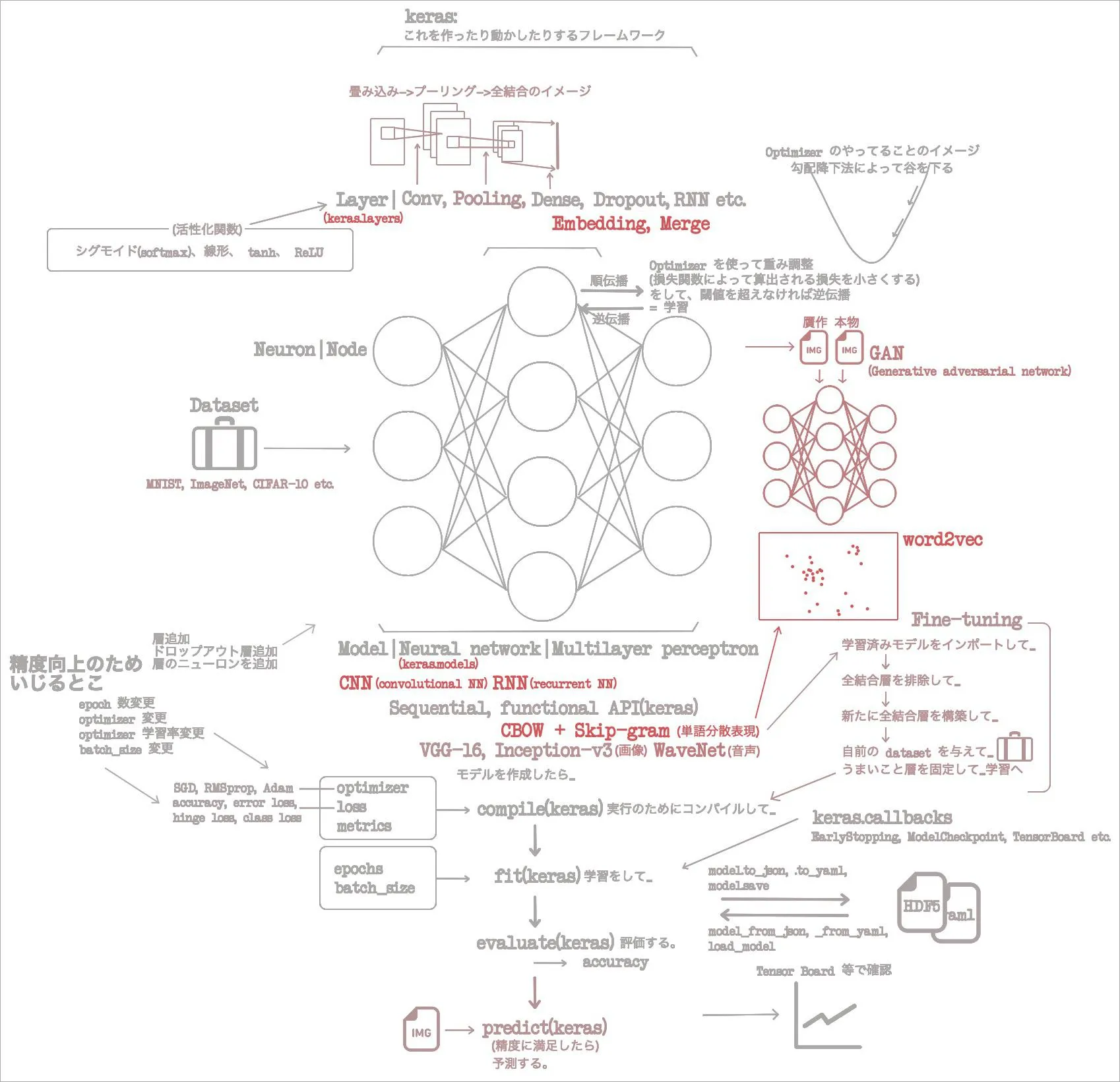
もうウチら畳み込みネットワークは極めたんじゃね?(慢心) ってカンジなので6章では RNN へいく。
6章をざっくり読んだ
6章のサンプルコード: https://github.com/oreilly-japan/deep-learning-with-keras-ja/tree/master/ch06
- この本って章の終わりに結構わかりやすい「まとめ」がある。最初に「まとめ」を読んで、自分が本章でたどることになる流れのイメージをつかんでおいたほうがラクに読めるかもしれない。
- RNN は CNN よりも系列データに対する能力が高いみたい。時系列とかね。
- RNN については、層という呼び方もしているし「RNN ユニット」って呼び方もしているみたい。ややこしいからヤメようね……。
- SimpleRNN には勾配消失、勾配爆発という問題があるみたい。
- SimpleRNN のかわりに LSTM GRU を使うとその問題がないみたい。
- RNN で出来ることには、株価等時系列データの予想、音声、音楽の生成、評判分析、機械翻訳、画像キャプション、テキスト分類、電力消費量の予測、品詞の予測があるみたい。
- ウン、最初に「まとめ」を読んで正解かも。6章の流れがなんとなくわかった。
- 「依存性のある入力」って何? ドラッグ?
- テキスト、音声、時系列データなどのこと。依存っていうのは、系列内の各要素が、それより前に現れた要素に依存するっていう意味の依存。
- たとえば "the dog" の次の単語は car よりも barks である可能性が高い。
- 畳み込み層をもつ NN が CNN だったように、リカレント層をもつ NN が RNN ということでいいの?
- そんな感じっぽいけれどリカレント層というものはなさそう。
- 代わりに RNN セルという名前のものがあるらしい。は……? 層ではないの? と読書中は困惑したけれど、層みたいに使うものという考えていて OK みたい。
- 具体的には SimpleRNN 層、 LSTM(long short-term memory)層、 GRU(gated recurrent unit)層、とかある。
- でも疑問があるよね。畳み込み層と RNN セルを混ぜたネットワークは何て名前になるの? 混ぜるな危険なの?
- ところで RNN でも学習では誤差逆伝播法(バックプロパゲーション)を使うよ。
- 何その英語、カッケ。最初に出てきたときに教えておいてくれ。
- SimpleRNN セルって何?
keras.layers.SimpleRNN- 上で先にまとめを読んでおいたおかげで、こいつには勾配消失、勾配爆発という問題があるため結局 Long Short-Term Memory や Gated Recurrent Unit に置き換えられることを知っている。これはあくまで前座であると思いながら読む。
- SimpleRNN に限らず、 RNN セルは、次のような作りになっている。
- 時刻 t のとき
- 入力 x(t) を受け付けて
- y(t) を出力する
- 扱うのは系列データなので、このときの出力は次の t(時刻)でも使いたい。だから一部フィードバックされる。それが h(t)
- この図はいつものマイ「イメージの流れ」図に追加しておこう。
- 十分わかりやすいのに、「入力 U 出力 V 隠れ状態 W」みたいな表し方もするんだって。めんど。
- で、その SimpleRNN が持つ問題である勾配消失と勾配爆発って?
- 消失と爆発の理屈、は何だか面倒くさくなってしまったので割愛。
- とにかく、勾配消失は、勾配がなくなって遠く離れたステップからの勾配が学習に何の貢献もしなくなることを意味する。
- とにかく、勾配爆発は、勾配が大きくなりすぎて学習が破綻することを意味する。
- いやしかし、「勾配」のことをイメージで押さえておいてよかったな。「学習とは最適化アルゴリズムが勾配降下法によって勾配を降らせることである」っていうイメージがなければ、勾配っていう単語の時点で脳死しているだろう。
- Long Short-Term Memory(LSTM)って何?
keras.layers.LSTM- 勾配消失問題を回避するバージョンの SimpleRNN。
- 両者の唯一の違いは勾配消失問題への強さらしいから、その理解でいいと思う。
- Gated Recurrent Unit(GRU)
keras.layers.GRU- Long Short-Term Memory の亜種。
- ほんの少し構造が違うので、場合によって使い分けたほうがいいみたい。
- GRU は、 LSTM よりも学習が早く、汎化に必要なデータが少なくて済む。
- LSTM は、データが十分あると、 GRU より精度がよい可能性がある。
- RNN のトポロジーって何?
- そもそもトポロジーって何。位相幾何学っていうらしいが……。
- RNN セルの基本は、セルごとに x(t) y(t) h(t) がある、というものだった。
- けれど、入力が最初の t だけってこともできるし(一対多)、出力が最後の t にしかない(他対一)もできるってことらしい。
- 双方向 RNN って何?
- ここまで↑の話では、時刻 t における RNN の出力は過去の t の出力に依存しとります。(ウンウン)
- だけど将来の出力に依存している可能性があります。(ナンデ?! ……まあいいや、そういうことがあるのね。)
- これを実現するときは、ふたつ RNN を用意して、ひとつは左から単語を読み、ひとつは右から読むイメージでネットワークを組む。
keras.layers.wrappers.Bidirectionalを使う。
- Stateful RNN って何?
- RNN は stateful である。
- まあそりゃわかるよ。フィードバックを次の t 時刻へ持ち越すもんね。
- ただし keras の RNN はデフォルトでは stateless である。
- えぇww
- ほとんどの問題は stateless RNN で解決できるので、 stateful RNN を使おうとするときは本当に必要なのか確認する必要がある。
- なんでかよくわからんけれど、 stateful の場合はデータを与える順番が影響するためデータをシャッフルできないなど縛りが発生する。そういう気をつけないといけないことが増えそうでイヤよね。
- RNN は stateful である。
- RNN の使用例。いくつか単語を与えたときに、次に出現する単語の確率を予測できます!
- ……使いみちのわからないものって、イマイチ感動しづらいよね。
- 「へぇー」と思ったのは、単語ベースでなく文字ベースでモデルを作り、「次の単語」ではなく「次の文字」を予測すること。
- Sequential -> add.SimpleRNN -> add.Dense -> add.Activation -> compile
- これまでと違うのは、ラベル付きデータがないこと。そういえばそうだ。正しい正しくないの情報がないもんね。
- だから1エポックずつ、人間が目で見てチェックする。
- https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch06/alice_chargen_rnn.py
- RNN の使用例。評判分析。
- 何それ……ああ、否定的レビューと肯定的レビューのことか。
- 次のようなものを予測するモデルを作るみたい。
- misson impossible 3 was excellent -> 肯定的
- i heard da vinci code sucked soo much only 2.5 starts -> 否定的
- https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch06/umich_sentiment_lstm.py
- RNN の使用例。品詞タグ付け。
- データセットとしては、品詞がタグ付けされた文が必要。 Penn Treebank を使う。
- Penn Treebank は有料データセットだけれど、 NLTK がそのうち10%を提供してくれている。有能。
- Natural Language Toolkit(NLTK)は5章で出てきた、データセットを良い感じに変換してくれる子よね。
- Sequential -> add.Embedding -> add.Dropout -> add.RepeatVector -> add.GRU -> add.TimeDistributed -> add.Activation -> compile
- なかなか複雑……なので実は1エポック以降過学習になる。そんなこともあるのか……。
- https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch06/pos_tagging_gru.py
こんなところで6章はおしまい。画像、音声、自然言語、に加えて、系列データを処理したわけだ。ざくざく読み進めているけれど、当然すっ飛ばしている要素も多い。とくに、 one-hot という手法はデータを用意するときによく使うみたいだけれど、これはよくわかっていないなー。マイ「イメージの流れ」図を更新して、今回もおしまい。