概要

UTF-8 が広く普及して、近ごろは、文字コードで悩むことなんてほとんどなくなったよな。いい時代になったものだ。しかし Windows サンが生み出す Shift_JIS と CP932 が和を乱すことがある。今日はそれについてまとめようぜ。
ぼくらは Shift_JIS のことは忘れて良い
というのも、 Shift_JIS は CP932 の部分集合なのだ。だから CP932 をカヴァーしてれば Shift_JIS をカヴァーしていることになるってことさ。
実験してみようぜ。
# まずは Shift_JIS でファイルを作る。
with open('shift_jis.txt', 'w', encoding='shift_jis') as f:
f.write('りんご')
# 次に CP932 でファイルを作る。
# '①②③' は Shift_JIS の領域外、 CP932 の領域内。
# CP932 領域の文字はこちら↓
# https://ja.wikipedia.org/wiki/Microsoftコードページ932
with open('cp932.txt', 'w', encoding='cp932') as f:
f.write('①②③')
# 一応確認。
# '①②③' は Shift_JIS に含まれないので Shift_JIS で書けない。
with open('cp932.txt', 'w', encoding='shift_jis') as f:
f.write('①②③')
# --> UnicodeEncodeError:
# 'shift_jis' codec can't encode character '\u2460' in position 0:
# illegal multibyte sequence
そんでこれらを読み込んでみる。
def detect_encoding(file_path: str) -> str:
"""
指定されたファイルのエンコーディングを検出する関数。
Parameters:
file_path (str): エンコーディングを検出したいファイルのパス。
Returns:
str: 検出されたエンコーディングに基づくメッセージ。
"""
with open(file_path, 'rb') as f:
data = f.read()
try:
data.decode('cp932')
return 'CP932 で読めたぜ'
except UnicodeDecodeError:
pass
try:
data.decode('shift_jis')
return 'Shift_JIS で読めたぜ'
except UnicodeDecodeError:
pass
return 'CP932 でも Shift_JIS でも読めなかったぜ'
print(detect_encoding('shift_jis.txt'))
# --> CP932 で読めたぜ
print(detect_encoding('cp932.txt'))
# --> CP932 で読めたぜ
ほらね。 CP932 は Shift_JIS を読めるから、ぼくらはもう Shift_JIS という文字コードを忘れていいってことさ。すべて CP932 でエンコーディングすればいい。しないけどな?? UTF-8 でエンコーディングするけどな??
ぼくらの VSCode のナメた挙動
上述のように Shift_JIS と CP932 には、間違えると UnicodeDecodeError を発生させる、大きな違いがある。しかし、ぼくらの愛する VSCode がナメた挙動を見せる。
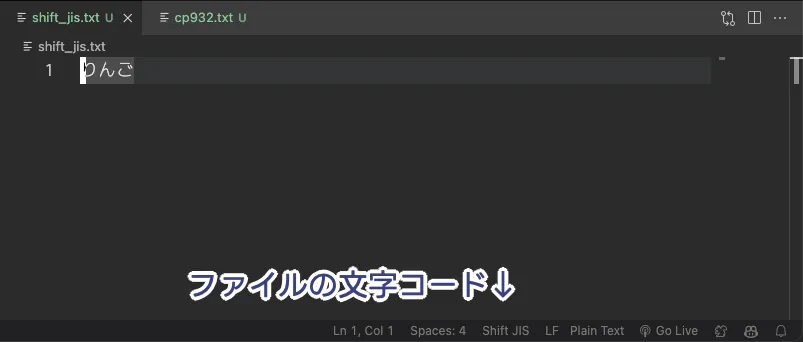
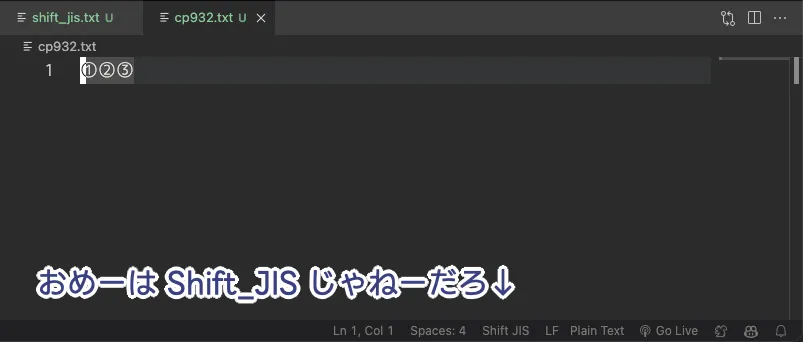
どうも Microsoft は拡張前の Shift_JIS も、拡張後の CP932 も、おしなべて Shift_JIS って呼んでいるらしいんだよな。おそらく VSCode は Microsoft 製だから、同じポリシーで文字コードを表記しているんだろうと思う。よくないと思うぜそういうの。
まあ Mac もたまに変な文字コードを寄越してくるが
UTF-8-Mac とかね。
文字コード関連記事の締めはいつも決まっている。良い子のみんなはおとなしく UTF-8 を使っておけよ。
なんで "良い子は UTF-8 を使っておけ" なのか
文字コードの歴史を辿ると、 Shift_JIS や CP932 はもともと日本で使われるために開発された。でも、これらの文字コードは国際的な規模での使用には限界がある。
- 言語サポートの制限: Shift_JIS や CP932 は日本語に特化している。だから、多言語対応のプロジェクトでは不便。
- 非標準的な拡張: CP932 などは、上述のように、独自の拡張が多い。これが互換性の問題を引き起こすことがある。
- エンコードの複雑性: UTF-8 は可変長エンコードだけど、それがうまく設計されている。一方で、Shift_JISやCP932は可変長でも、その設計が古く、今の環境には合わない場合がある。
これらの制限が UTF-8 のようなよりユニバーサルな文字コードが求められる理由だよ。 UTF-8 は複数の言語をサポートし、エンコードも効率的なんだ。だから、 "良い子は UTF-8 を使っておけ" というわけだ。