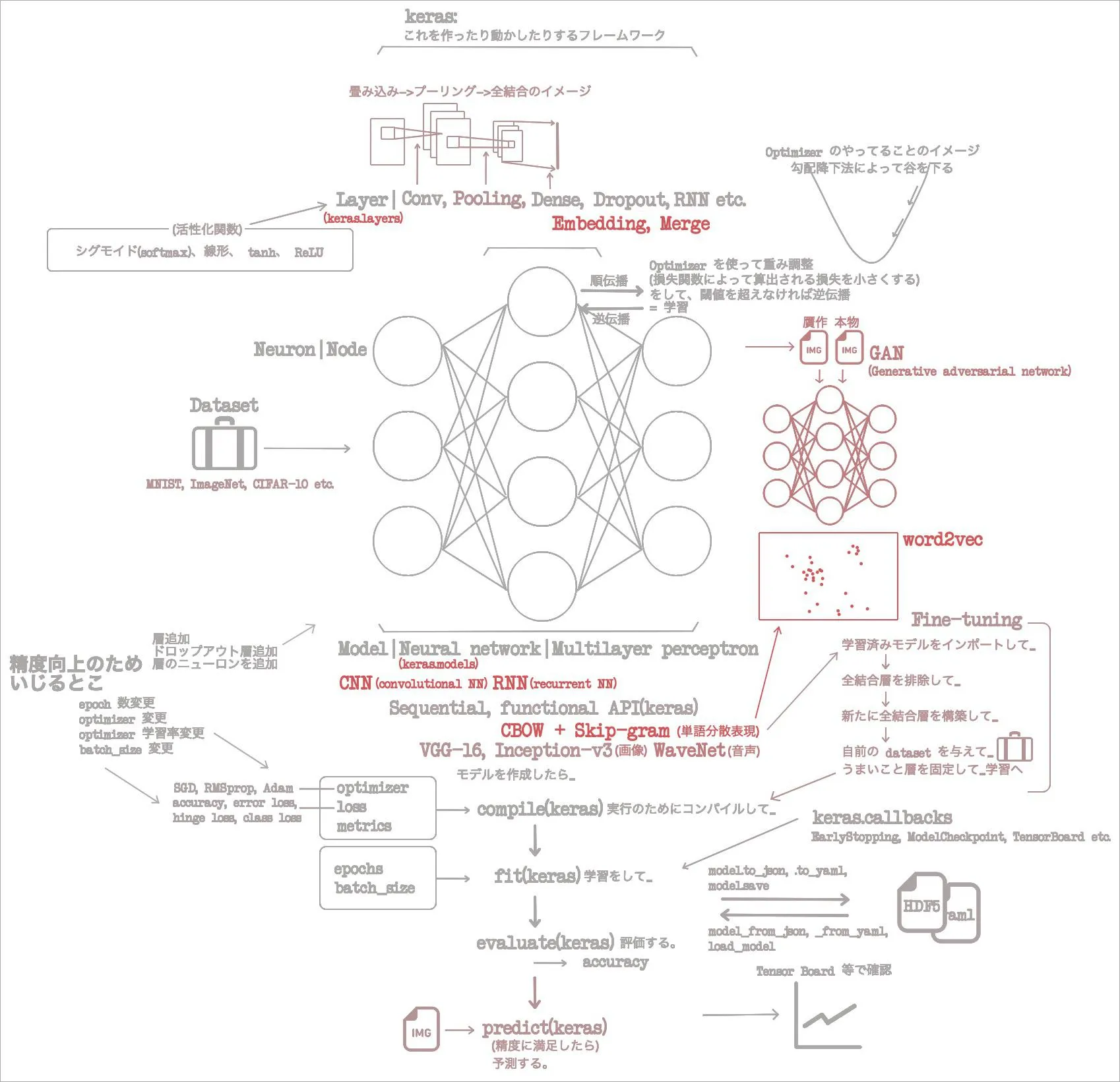
概要
前回までの続き。
- (2021-06-16)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み1章 ニューラルネットワークの基礎
- (2021-06-17)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み2章 Keras のインストールと API
- (2021-06-18)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み3章 畳み込みニューラルネットワーク
- (2021-06-19)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み4章 GAN と WaveNet
1章で概念と用語をざっと回収、2章でそれらが Keras でなんてクラスに相当するのか回収。3章では CNN を使って画像分類タスクを撃破。4章では CNN がふたつ出てきて画像贋作タスクをこなした。さらに画像という枠を出て音声まで生成しだした。
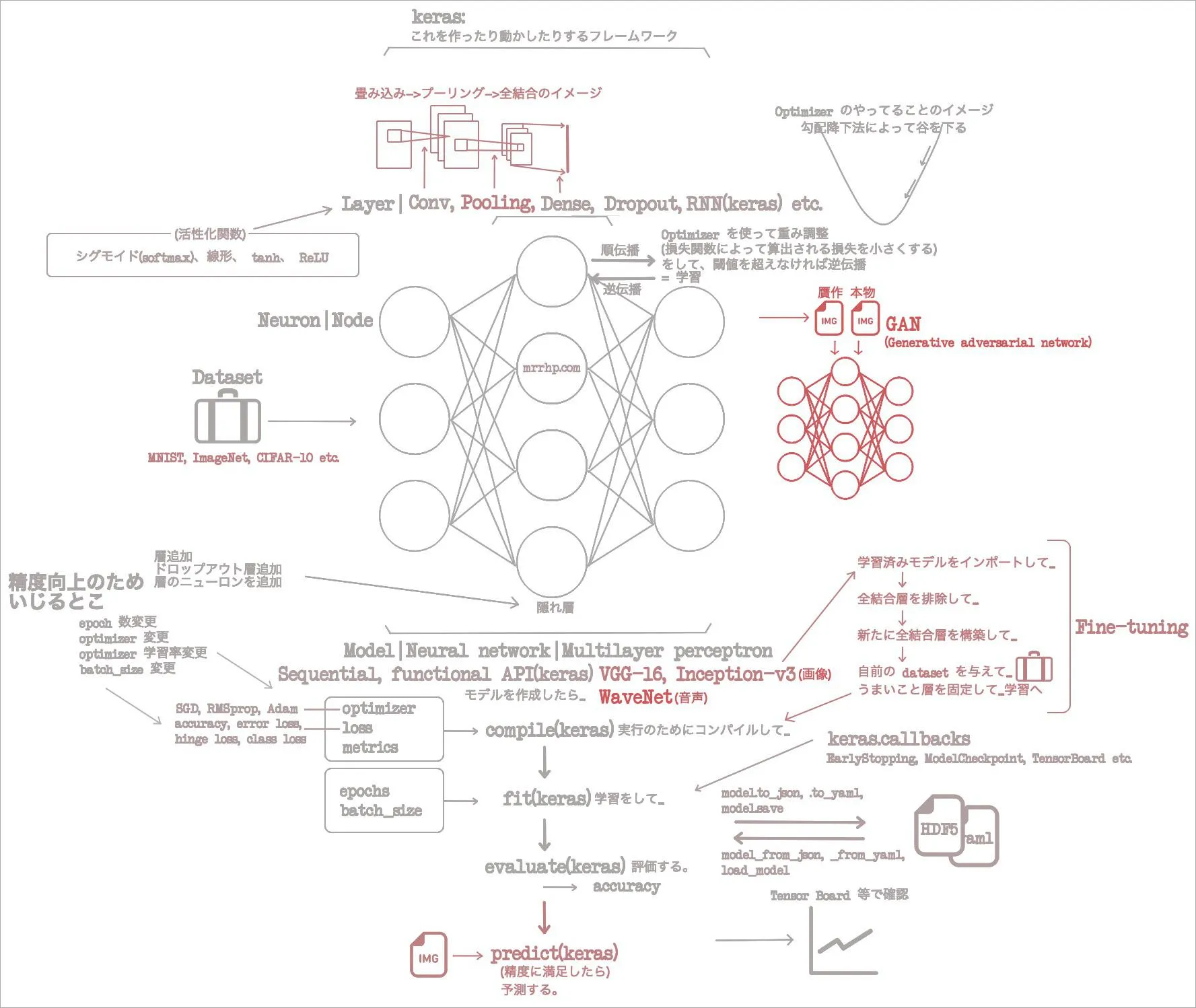
画像、音声、ときて次は自然言語処理だ。これも Python コミュニティの意識高い人たちが好きなやつだね。今更だけれど、 keras って画像だけが対象なわけではないんだね。モデル次第で色々できる。
5章をざっくり読んだ
- 自然言語処理は、単語を分散表現するところからはじまる。分散表現って何?
- マジで何? なんだけれど、「イメージ」としては、グラフ上に単語が配置されているやつ。似た意味のやつほど近くに配置されるやつ。この説明で、あー、なるほどとなるだろう。
- どうやってそんなグラフ作る?
- 「似た文脈を持つ単語は似た意味を持つ(You shall know a word by the company it keeps)」という考えを軸にやる。
- たとえばこんな↓ふたつの文章があるとき……
- Paris is the capital of France.
- Berlin is the capital of Germany.
Paris : France::Berlin : Germanyの関係があることが直感的にわかる。いや、この表記は全然知らないけど、何が言いたいかはわかる。何これ。数学の表記?- こうやって、意味的に近い(この場合は Paris & Berlin が近くて、 France & Germany が近いってことよね)単語を割り出して、グラフ上に分散表現するというワケだな。
- それを実現するのが word2vec だ。それって何?
- CBOW(continuous bag-of-words)と Skip-gram ふたつのアーキテクチャでできた分散表現。
- CBOW が文脈語から中心語を予測するモデル。 keras に組み込まれているようなものじゃなく、実現するには自分で層を重ねる。
- Skip-gram が中心語から文脈語を予測するモデル。同上。
- さっきから言ってる文脈語と中心語って何?
- 次のような文章において……
- I love green eggs and ham.
- (文脈語, 中心語) = ([I, green], love) ([love, eggs], green) などなど。
- ああ、文の中にある単語と、その周辺にある単語の組み合わせのことね。
- ちなみにこの分ける作業は、ちゃんと
keras.preprocessing.textがやってくれる。画像のときはkeras.preprocessing.image.ImageDataGeneratorとか使ったよねえ。 preprocessing は、データセットを加工して学習の手伝いをしてくれる。私覚えてるわよ。 - https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch05/skipgram_example.py
- 次のような文章において……
- Green eggs and ham って何?
- なんか有名な絵本らしいよ。こちらはオバマ大統領が朗読している動画: https://www.youtube.com/watch?v=imFTk5exiDY
- word2vec のためのモデル CBOW と Skip-gram はどう作るの?
- 今回新出の
keras.layers.Embeddingとかkeras.layers.Mergeを使って作れないことはない。 - https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch05/keras_cbow.py
- これらをふたつ作って、こんな↓感じでくっつける。
- Sequential -> add.Merge([中心語用モデル, 文脈語用モデル]) -> add.Dense -> compile
- https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch05/keras_skipgram.py
- ぼくは
softmaxとsigmoidを混同していたので、ここ↑の Dense でsigmoidが突然使われだしたので驚いちゃったのだけど、このふたつは似ているけれど違う活性化関数みたいね。
- ぼくは
- 作れないことはない、のだけど、実際はサードパーティライブラリで簡単にインポートできるよ。
- 今回新出の
- gensim って何?
- word2vec を一瞬で
gensim.models.word2vecで使えるライブラリ。 - サンプルコードはこちら↓だけど、学習したあとでコイツを使う雰囲気をノートしておこう。「イメージの流れ」を押さえておくの大事。
- word2vec を一瞬で
- word2vec の使用イメージ。
list(model.wv.vocab.keys())[0:10]モデルに含まれる単語を羅列。model['woman']単語を与えると、分散表現(グラフ上のどこにあるか)を得られる。model.most_similar('woman')類似の単語を得られる。あ、おもろ。model.most_similar(positive=['woman' , 'king'], negative=['man'], topn=10)woman, king と似ていて man と似ていない単語(queen)を得られる。何これおもろ!model.similarity('girl', 'woman')ふたつの単語の類似度を出す。- いや〜、使用イメージが得られると満足度高いですねい。分散表現はもうおなかいっぱいですわい。
- GloVe
- まだあんのかよ。
- word2vec は予測ベースの分散表現だったが GloVe はカウントベース。
- もうおなかいっぱいなので面倒になってきたが、大丈夫。これは Python のツールが充実してないし今のとこは忘れてよい。
- いくつか分散表現実装の例を。まず、ゼロから分散表現を学習する戦略で、文章をネガティブ、ポジティブに分類。
- これ、昔やりたがってる友達いたなー。
- Embedding 層を使って行う、デフォルトのやり方。
- データセットとしては、 Kaggle の UMICH SI650 評判分析コンテストのを使う。7000文含まれている。
- データセットを単語 ID の系列データに変換するためには(……何て? えー、 preprocessing がやってくれるようなやつ?)、 NLTK(Natural Language Toolkit)を使う。
- https://www.nltk.org/install.html, https://www.nltk.org/data.html
- 手順的には、 Sequential -> add.Embedding -> add.Dropout -> add.Convolution1D -> add.GlobalMaxPooling1D -> add.Dense になる。あ、そっか、画像じゃなくて線形である文だから 1D なんだ。
- https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch05/learn_embedding_from_scratch.py
- えー、これ、使ってみたいけれど、学習するだけで使ってみるところが書いてなくない? これは課題だな、モデルさえあれば自由に predict できる方法を自分で押さえておきたい。
- 次に、学習済み word2vec を fine-tuning する戦略。
- さっき↑と同じデータセットを使うのだけど、今度は Google ニュース記事を学習したモデルを使う。
- その垂涎ばかうまモデルはここからダウンロード出来るっぽい: https://code.google.com/archive/p/word2vec/
- https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch05/finetune_word2vec_embeddings.py
- 10エポックで99%の精度。
- 最後に学習済みの重みをそのままアプリケーションで使用。
- https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch05/transfer_word2vec_embeddings.py
- 10エポックで97%の精度。
- もし自分で試すとしたら、「そのまま」をやってから「fine-tuning」かな。難易度的に。
- ところですごく良い文あった。
- 「損失関数 categorical_crossentropy は2クラス以上の分類をする場合によく使われる」。
- そうそう。複数選択肢があるときはそーゆー目安が欲しいのだよ。
こんなところで5章はおしまい。イケイケで意識の高い Pythonista サンたちがよくやっている自然言語処理の一端をかじることができたな。自然言語処理なんつーのは Pythonista 業界で言えば銀座だからな。それで言えばぼくが居るのは新潟みたいなもんだ。
今回の章では畳み込みニューラルネットワーク(CNN)でテキストデータを学習したけれど、これって、もっと向いているネットワークがあるらしい。リカレントニューラルネットワーク(RNN)がそれだ。え? すでに99%の精度を達成しているのに、まだ上があるわけ? 意味不明。けれど、そうか。そもそも CNN を使い出したのって、 2D の学習に向いているからだもんね。テキストデータは 1D だから、 CNN を使う意味がそもそもないのか。マイ「イメージの流れ」図を更新して、今回もおしまい。