概要
前回までの続き。
- (2021-06-16)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み1章 ニューラルネットワークの基礎
- (2021-06-17)Antonio Gulli and Sujit Pal『直感 Deep Learning』 ざっくり読み2章 Keras のインストールと API
1章では機械学習関連の概念と用語をざっと回収し、2章ではそれらを Keras フレームワークで使うには実際にどのクラスになるのかを回収したな。
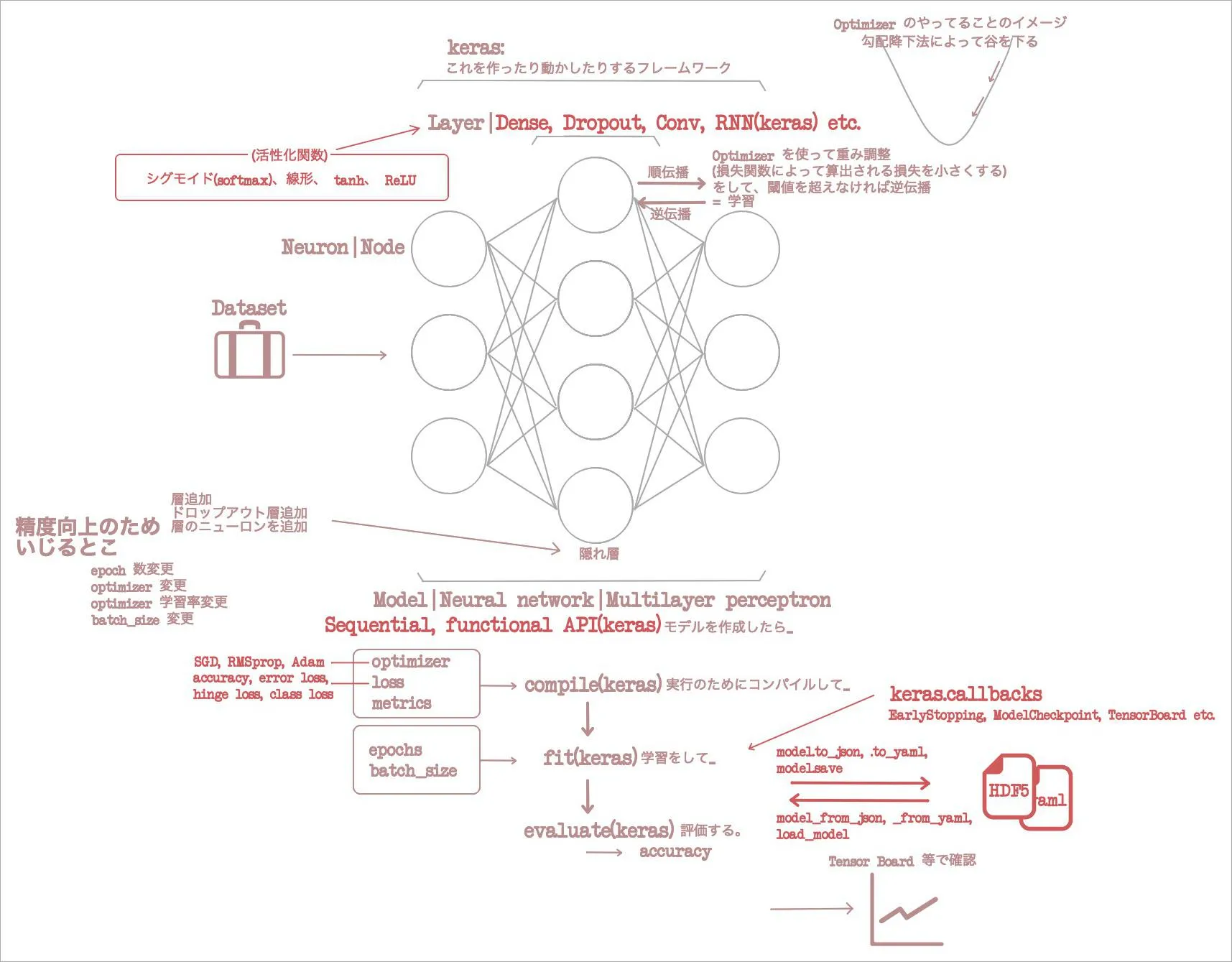
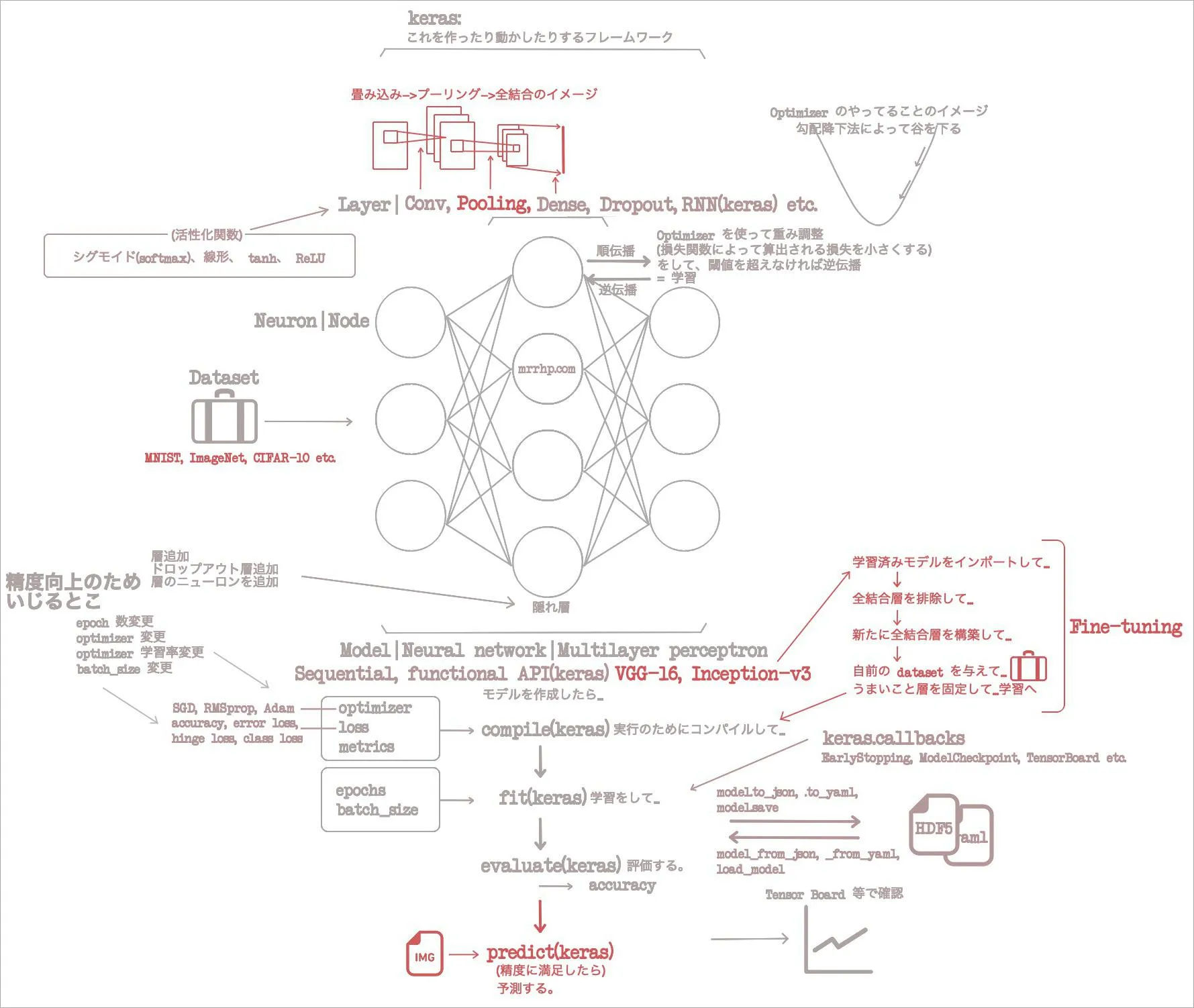
3章はだな、図の、 Layer のところに Conv という層があるじゃん? これがどういうもんなのか、そして何の役に立つのか、やる。先に言っちゃうと画像分類に無類の能力を発揮するヤツらしい。
3章をざっくり読んだ
3章のサンプルコード: https://github.com/oreilly-japan/deep-learning-with-keras-ja/tree/master/ch03
Conv1DConv2Dって何? ぼくは完全に「昆布層」って呼んでいるけど。- これは「畳み込み層」という。 Convolutional layer なので昆布層ね。
Denseは全結合層で、隣接する層のノードに全結合である、ってマジ?- おいおいそのイメージは新出だぞ。2章で言っといてくれ。めっちゃいいイメージじゃん。
- こいつは画像イメージを扱うときピクセルを全部1次元に(線形に)並べちゃうから、ピクセルから空間的特徴が失われちゃう。
- 並べるだけだから、四方八方の関連性が失われるってことか。「空間」って言葉からは初見では3次元の印象を受けちゃったけど、2次元も空間なのね。イメージ修正完了デス。
- 一方で
Convは空間を捉えられるので画像の分類に適している。ピクセルを並べないってこと?- 「ピクセルを並べない」をカッコよくいうと「画像内の空間情報を維持する」という。次のような手順で、「空間情報を維持」する。
- 1 元画像の一定領域を「畳み込む領域」と決める。
- 2 その領域を次のレイヤーのひとつのノードに接続する。接続されたノードを「局所受容野」という。
- 3 この↑接続処理を畳み込みという。
- 4 「畳み込む領域=5x5」「元画像=28x28」「1px ずつずらして」局所受容野を作っていくと、24*24のマトリクスができる。(5x5ピクセルの画像が576枚できるってことよね?)この、「できあがったもの」を「特徴マップ feature map」という。
- さあそろそろイメージができなくなってきた。単語だけ並べて「イメージの流れ」を作ろう。
畳み込む領域を…… -> 局所受容野に接続して…… -> 結果として特徴マップができる。 - なお「畳み込む領域を5x5と決めること」を「5x5のフィルターを使う」と言うらしい。もうわからんこういうのは言い回し同士をてきとうにイコールづけていくしかない。
- 具体的な話をしよう。 Keras で表現するならどうなるの?
- こう↓だ。
model.add(keras.layers.convolutional.Conv2D(
# フィルターの数。
# 「数」って意味不明。「畳み込む領域」のサイズと「元画像」のサイズが決まればオートで決まらね?
20,
# これは「畳み込む領域」のサイズ。
kernel_size=5,
# 特徴マップのサイズと元画像のサイズを同じにするなら same。でないなら valide(まったくわからん)。
padding='same',
# 元画像のサイズ。これ↓なら 256x256 RGB
input_shape=(256, 256, 3),
# 活性化関数。そうそう、自作の図にもあるように、層には活性化関数を与えるのよね。
activation='relu',
))
- あと、実は畳み込み層の次にはプーリング層を重ねないといけない、という法律があるらしい。(ない。冗談だ。でもそういう構造にするものらしい。)
- Pooling は特徴マップのサイズを圧縮する行為。いや、わからん。
- こういう↓イメージだけ把握しとこ。
- なお、最初に(画像に向いてないっつって)ディスった全結合層だけど、結局最終的には全結合層に接続する。
"""こういう数値の領域があるとき……
1,0,3,6
2,4,5,2
1,6,2,0
3,4,1,7
"""
# プーリング層によって圧縮すると……
model.add(keras.layers.pooling.MaxPooling2D(
pool_size=(2, 2),
strides=(2, 2),
))
"""こう圧縮される。
4,6
6,7
"""
- LeNet って何?
- 最初期の畳み込みニューラルネットワーク。
- なんか「畳み込みニューラルネットワーク」って言葉使われてるけど、畳み込み層が使われているニューラルネットワークのことかね?
- LeNet を実装しているサンプルコードはこちら: https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch03/lenet.py
- CIFAR-10 って何?
- データセット。60,000件の画像。32x32サイズ。10クラスが含まれる(10種ってことね airplane, automobile... とか10個)。
- CIFAR-10 を使って73%くらいまで精度を上げるサンプル: https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch03/cifar10_net.py
- それにさらに畳み込み層を足して76%くらいまで精度を上げるサンプル: https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch03/cifar10_deep_net.py
- それに Data Augmentation を加えて78%くらいまで精度を上げるサンプル: https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch03/cifar10_deep_with_aug.py
- ↑で作ったモデルファイル hdf5 をロードして予測を行うサンプル: https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch03/cifar10_predict.py
- 待て待て、ここに来て一気に宝の山だ。ずっと、任意の画像に「何々である確率何パーセント」を出す話が出てこないことが不満だったんだけれど、一気にサンプルコードが出てきた。
- なお↑で出てきた Data Augmentation とは、
keras.preprocessing.image.ImageDataGeneratorを使って、画像を回転させたり左右反転させたりして学習データを水増しする hack のことだ。
- このあたりからサンプルコードで model を定義する処理を関数化するようになってきて、いいね。全部ベタ書きしているより好き。モデルを作る関数名が
networkなのだけがわかりづらいけど。create_modelとかにしてよ……? - VGG-16 って何?
- 16層のモデル。2014年に発表された論文の中で構築されたモデルのひとつ。1000クラス含まれている。
- ImageNet ILSVRC-2012 データセットを使って学習して93%の精度を叩き出している。
- ImageNet Large Scale Visual Recognition Challenge
keras.applications.VGG16で学習済みモデルを利用できる。keras.applicationsには他にも構築済み、学習済みの model が入っている。- これを使えば13行くらいで予測までやれる。サンプルはこれ: https://github.com/oreilly-japan/deep-learning-with-keras-ja/blob/master/ch03/pretrain_vgg.py
- ネットワークの重みは、モデルがインスタンス化されるときにダウンロードされる。マジじゃん↓
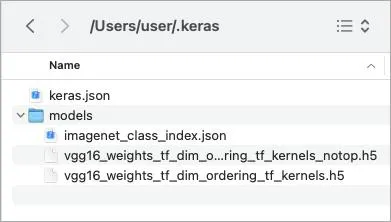
- ImageNet って何?
- 1400万の画像。2万を超えるクラス。のデータセット。
- 転移学習って何?
- Transfer learning. すでに学習されたモデルを他の新しいタスクに適用すること。
- ぼくはもともと fine tuning を知っているから、「え? Transfer learning ではなくて fine tuning でしょ?」って思ったけれど、 transfer learning というくくりの中に fine tuning があるってことみたい。
- Fine tuning って何?
- データを沢山用意できないときに使う transfer learning だ。
- 事前学習済みのモデルの一部を変更して、再学習する手法。
- 「本節では、 ImageNet で学習されたモデルを他の画像分類のタスクに適応させる方法を……」そうそう、わかる。実は今回の読書は、緑さん自身でググりまくって一度コレを試したあとに行っている。
- ぼくがググりまくってやったときは先述の VGG-16 で fine tuning を試したんだけど、ここでは Inception-v3 モデルでやっている。
- Inception-v3 って何?
- 入力サイズ 299x299x3 のモデルで、これも VGG-16 と同じく ImageNet で学習されている。 VGG-16 の兄弟みたいなもんだと思って良いか?
- Inception-v3 を使った fine tuning は GitHub ではなく Keras の公式にある。ただこれは一部省略されていたりして、コピペで動かすわけにはいかないようだ。: https://keras.io/api/applications/#finetune-inceptionv3-on-a-new-set-of-classes
- Fine tuning のサンプルコードは、ちと難解で、しっかりイメージを掴むには自分で動かしながらやるしかないみたいだ。でもちゃんと今回のテーマどおり「ざっくり」まとめておく。
- 1 学習済みモデルをインポート。
- 2 上位の層を除くため、
include_top=Falseパラメータを与えてインスタンス化する。 - あれ……? 上位ってどっち……? 入力層に近い方? 出力層に近い方……? ンモー、このへんがわかんねんだよ。
- 3 除いた層の代わりの全結合層を構築する。ここでネットワークの定義は完了。
- 4 学習に入る。ただし、新しく付け加えた層のみ学習するので、もともとの層には
layer.trainable = Falseを指定する。 - 5 コンパイル -> 学習。これはまだ fine tuning ではないらしい。
- 6 今は「ImageNet で学習した層」「新しいタスクで学習した層」にキッチリ分かれちゃっているから、「ImageNet 学習層」「どっちも学習した層」「新タスク学習層」を作る。これが fine tuning らしい。
layer.trainable = [False or True]を適切な層で区切って設定する。この属性をいじったあとは、ちゃんとコンパイルしてから学習する。
こんなところで3章はおしまい。ごちゃごちゃしてきたが、流れとしては……「1章: ニューラルネットワークの全体」「2章: それを keras で表現」「3章: ニューラルネットワークの中でも主要な『畳み込み層』を概念、 keras 両方で解説し、それを使った実践」……と、順調に流れてきているね。難度はぶち上がったと思うけれど。
上述したように、ぼくは本書を読む前にある程度ググって、 keras を使って、 VGG-16 を改造して fine-tuning をすでに試している。そのあとに本書を読み出して、 fine-tuning の節までやってきた。細かい不理解が埋まって、不思議な満足感がある。まるで、運動しまくって栄養が枯渇したスカスカの筋肉に水やタンパク質が染み込んでいくときのような感じ。いや、ちょっと待って、馴染む表現をしたつもりがマッチョ理論みたいになっちまった。ともかく。今回もマイ「イメージの流れ」図を更新したぜ。