Overview

UTF-8 has become widely adopted, and nowadays, we hardly ever have to worry about character encoding issues. It's a good time to be alive. However, the harmony can sometimes be disturbed by Shift_JIS and CP932, character encodings that Windows tends to use. Today, let's dive into that topic.
We Can Forget About Shift_JIS
The reason is that Shift_JIS is actually a subset of CP932. So, by covering CP932, you're also essentially covering Shift_JIS.
Let's run some experiments.
# First, create a file with Shift_JIS encoding.
with open('shift_jis.txt', 'w', encoding='shift_jis') as f:
f.write('りんご')
# Then, create a file with CP932 encoding.
# '①②③' falls outside of the Shift_JIS range but within CP932.
# You can find CP932 specific characters here↓
# https://ja.wikipedia.org/wiki/Microsoftコードページ932
with open('cp932.txt', 'w', encoding='cp932') as f:
f.write('①②③')
# Let's check if it's working.
# '①②③' is not in Shift_JIS so you can't write it with that encoding.
with open('cp932.txt', 'w', encoding='shift_jis') as f:
f.write('①②③')
# --> UnicodeEncodeError:
# 'shift_jis' codec can't encode character '\u2460' in position 0:
# illegal multibyte sequence
And then let's read these files.
def detect_encoding(file_path: str) -> str:
"""
A function that detects the encoding of the specified file.
Parameters:
file_path (str): The path of the file you want to detect the encoding for.
Returns:
str: A message based on the detected encoding.
"""
with open(file_path, 'rb') as f:
data = f.read()
try:
data.decode('cp932')
return 'Readable with CP932'
except UnicodeDecodeError:
pass
try:
data.decode('shift_jis')
return 'Readable with Shift_JIS'
except UnicodeDecodeError:
pass
return 'Not readable with either CP932 or Shift_JIS'
print(detect_encoding('shift_jis.txt'))
# --> Readable with CP932
print(detect_encoding('cp932.txt'))
# --> Readable with CP932
See? Since CP932 can read Shift_JIS, we can forget about the latter. Just encode everything in CP932. But we won't, right? We'll use UTF-8 anyway!
The Cheeky Behavior of Our Beloved VSCode
As previously mentioned, there is a significant difference between Shift_JIS and CP932, a mistake in which can result in a UnicodeDecodeError. However, our dear VSCode shows some cheeky behavior regarding this.
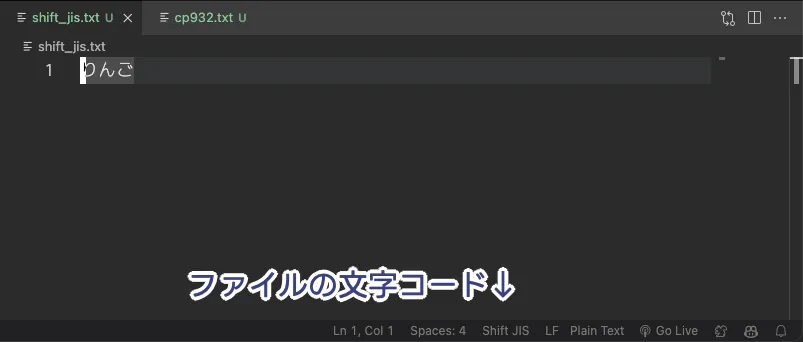
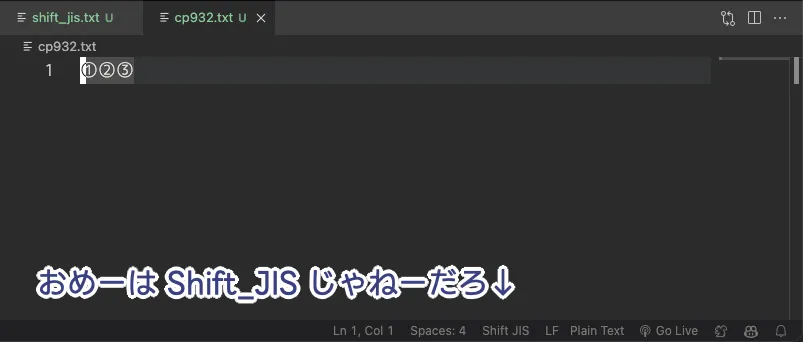
It seems that Microsoft refers to both the pre-extension Shift_JIS and the post-extension CP932 as simply Shift_JIS. Probably because VSCode is a Microsoft product, it follows the same policy in displaying character encodings. I don't think that's a good thing, you know?
Well, Mac Also Sends Over Some Weird Character Encodings Once in a While
Like UTF-8-Mac, for instance.
The conclusion for articles about character encoding is always the same. All the good kids out there should just stick to using UTF-8.
Why Should "Good Kids Use UTF-8"?
When tracing the history of character encoding, Shift_JIS and CP932 were originally developed for use in Japan. However, these character sets have limitations when it comes to international scalability.
- Language Support Limitations: Shift_JIS and CP932 are specialized for Japanese. Therefore, they're inconvenient for projects that require multi-language support.
- Non-Standard Extensions: As mentioned earlier, CP932 and the like have a lot of unique extensions. This can lead to compatibility issues.
- Complexity of Encoding: UTF-8 uses variable-length encoding but is well-designed. On the other hand, while Shift_JIS and CP932 also use variable-length encoding, their older design can be incompatible with modern environments.
These limitations are why more "universal" character sets like UTF-8 are preferred. UTF-8 supports multiple languages and its encoding is efficient. That's why the saying goes, "Good kids use UTF-8."